

Introduction
Everybody knows JSON, it’s a simple serialization format and the default format for REST APIs. Like many other topics, there are fine points you should know in order to work with JSON more effectively and avoid common mistakes.
In this article we’ll explore some big picture aspects and some low level details of using JSON.
Serialization
Before diving into JSON, I’d like to take a look at serialization in general and discuss common mistakes I’ve seen my customers make.
Serialization is the process of converting a value into bytes on one side and then converting the bytes back to a value on the other side.
The question is: Why do you need serialization?
The answer is that under the hood, computers store everything in bytes. When you need to transfer data between two pieces of code that don’t share memory, you first need to serialize the data and then transfer it. You’ll use serialization in network operations, saving data to disk, with databases, and more.
Common Serialization Mistakes
I’d like to start with covering some common serialization mistakes. I’ve seen these mistakes regardless of the serialization format (JSON, YAML, TOML, Protocol buffers, flat buffers …).
Passing Serialized Data In Regular Function Calls
The first mistake I see is to pass the serialized data between code that does share the same memory space, which leads to inefficient code that wastes both CPU and memory.
For example, say you serialize a time value to a string ("2024-08-19T12:12:39.295144041Z") to use as a parameter to another function. This means that when the function accepts the string and wants to do some date related operations, say get the year, it needs to call time.Parse first to convert it back to a time.Time value. You should serialize only at the “edges” of your program, where it interacts with the outside world.
Using The Same Data Structures In Different Layers
The second mistake is using the same data structure in different layers of your code.
It’s convenient to receive a request for a document, pluck it from the database (say Elasticsearch), and return it “as is” to the client. But, in this case you are tying the storage layer data model to the API layer. Say you make a change to the database schema, now you have changed your API, or even exposed some sensitive data to the user of the API.
Many applications should have three major layers: API, Business, and Storage. Each of these layers have a different development velocity (the rate at which the code changes over time). The API layer has low to zero velocity, the business layer has high velocity, and the storage layer has medium velocity.
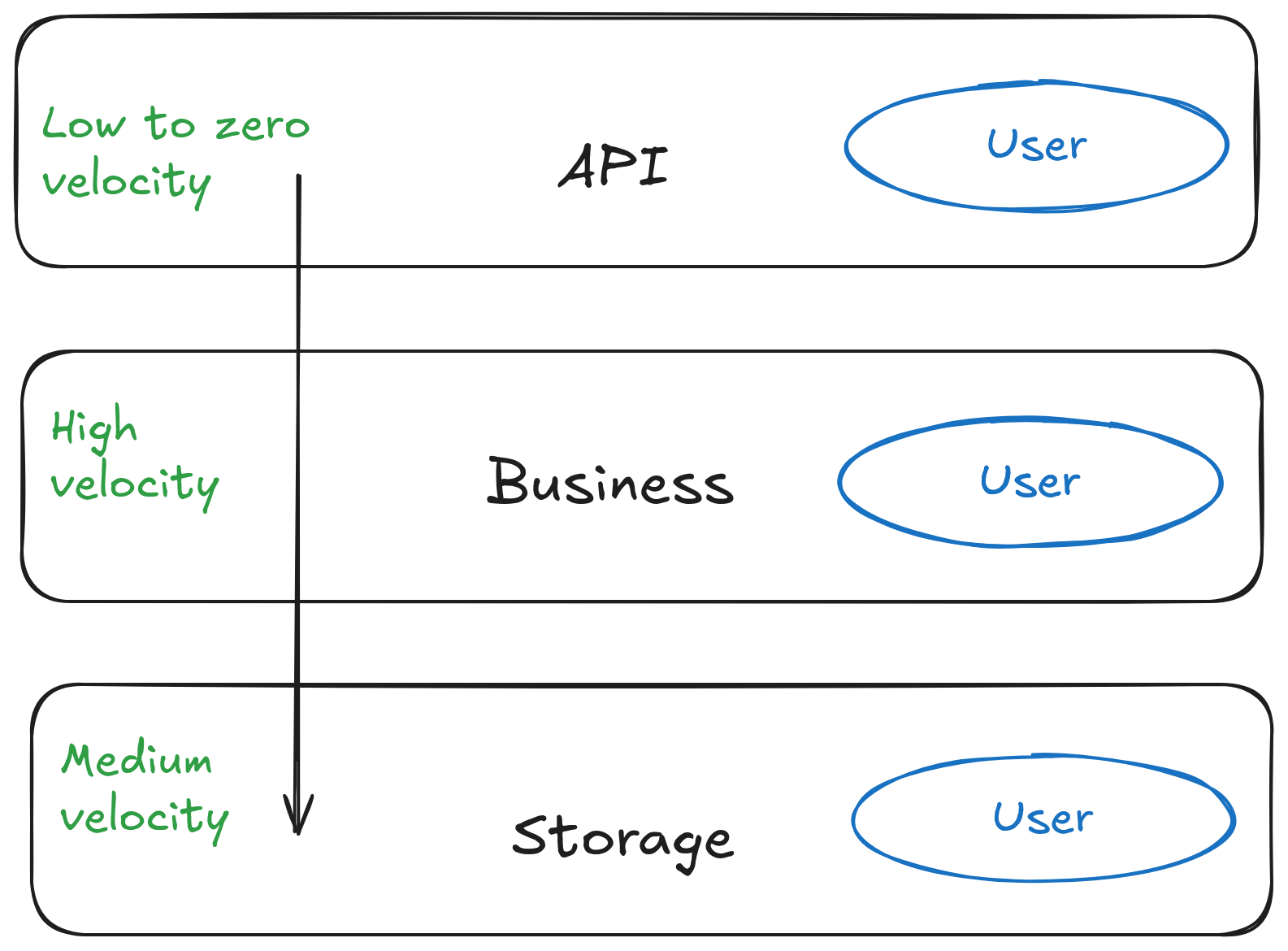
As an example of change velocity, let’s run through a scenario.
Say you have a User type in your system and you decide to use a single type for all three layers instead of giving each layer their own User type. After a while, the data team adds an “address” field to the user in the database, but the API layer shouldn’t export that address to the client due to privacy concerns. If you keep a different User type per layer, you can make database schema changes without affecting your API.
Not Validating Incoming Data
The third mistake is assuming that valid JSON (or XML or gob or …) is valid data.
Consider the following request:
Listing 1: A JSON Request
01 {
02 "car_id": "CAR3",
03 "lat": 0.7579787,
04 "lng": 193.9881175,
05 "passenger_count": 3,
06 "shared": true
07 }
Listing 1 shows a JSON request. The request is provided with a valid JSON document, but the longitude (lng) value is above the maximal longitude value of 180.
Apart from data integrity, some malicious actors use bad values to try to crash your system.
You can use libraries such as validator, cue, and others to combat this, but you can also write your own validation logic in code.
Follow these rules to avoid the common mistakes we have discussed:
- Serialize only at the “edges” of your program
- Have a separate data type per application layer (API, business and storage)
- Always validate incoming data
JSON
JSON is a text based format without schema.
Being text based makes JSON readable to humans, but you pay a price in the number of bytes needed to encode the data. For example, you can encode the number 123 in a single byte, but in JSON it’s encoded as a string which is three bytes.
Having no schema means you can quickly develop and change the data. But, no schema means you need to work harder on validating incoming data.
Types
Every serialization protocol defines its own set of data types and those types don’t always match 1-to-1 with the types in a programming language. A programmer has to figure out how to map the types.
In Go, we map the types for JSON like this:
| JSON Type | Go Type(s) |
|-----------|-------------------------------------------------------------|
| string | string |
| number | float64, float32, int, int8, ... int64, uint8 ... uint64 |
| boolean | bool |
| null | nil |
| array | []T, []any |
| object | struct, map[string]any |
Some points to consider:
- Only pointers and Go’s internal types can be
nil, but a value of any type does have a zero-value state. A string can’t benil, but it can be empty. Go doesn’t have the concept ofnull(the absence of value), but in Go we tend to usenilasnullwhen we can. Sometimes we try to use zero value, but in many cases that is not accurate. In JSON any field can benullwhen it’s not provided. As a Go programmer you need to decide whether to use pointers or zero-value to representnull. - JSON has one number type, Go has many (int, int8, int16, … int64, uint, … uint64, float32, float64, …)
- JSON arrays can have mixed types, Go slices can’t - unless you use
[]any, which hard to work with since you need to do type assertions all the time - Using structs, you can give
encoding/jsonhints on how to convert JSON types to Go types. - Some types are missing from JSON
timestamplike Go’stime.Time.- Binary type such as Go’s
[]byte.
encoding/json API
Go has built-in support for JSON serialization via the encoding/json package. This package defines the following APIs:
| From | Via | To | Method |
|------|-----------|------|-----------------|
| JSON | bytes | Go | json.Unmarshal |
| Go | bytes | JSON | json.Marshal |
| JSON | io.Reader | Go | json.NewDecoder |
| Go | io.Writer | JSON | json.NewEncoder |
encoding/json can work using a []byte or with io.Reader and io.Writer for streaming operations.
Pick the right method depending on the situation.
For example, if you decode an incoming HTTP request body that implements io.Reader, use json.NewDecoder.
Conclusion
In this article I’ve covered the general principles of working with serialization and looked at the encoding/json API. I hope it helped you get a better grasp on the topic. In the next articles I’ll dive into details of serializing (marshaling) JSON and de-serializing (unmarshalling).


