

If you are coming to Go after using a programming language like C# or Java, the first thing you will discover is that there are no traditional collection types like List and Dictionary. That really threw me off for months. I found a package called container/list and gravitated to using it for almost everything.
Something in the back of my head kept nagging me. It didn’t make any sense that the language designers would not directly support managing a collection of unknown length. Everyone talks about how slices are widely used in the language and here I am only using them when I have a well defined capacity or they are returned to me by some function. Something is wrong!!
So I wrote an article earlier in the month that took the covers off of slices in a hope that I would find some magic that I was missing. I now know how slices work but at the end of the day, I still had an array that would have to grow. I was taught in school that linked lists were more efficient and gave you a better way to store large collections of data. Especially when the number of items you need to collect is unknown. It made sense to me.
When I thought about using an empty slice, I had this very WRONG picture in my head:
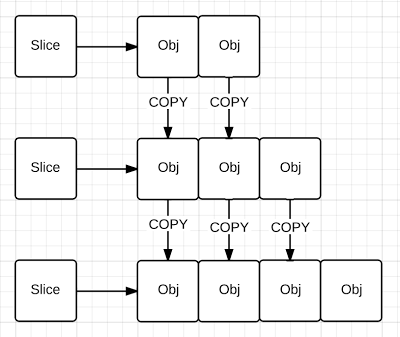
I kept thinking how Go would be creating a lot of new slice values and lots of other memory allocations for the underlying array with values constantly being copied. Then the garbage collector would be overworked because of all these little values being created and discarded.
I could not imagine having to do this potentially thousands of times. There had to be a better way or efficiencies that I was not aware of.
After researching and asking a lot of questions, I came to the conclusion that in most practical cases using a slice is better than using a linked list. This is why the language designers have spent the time making slices work as efficiently as possible and didn't introduce collection types into the language.
We can talk about edge cases and performance numbers all day long but Go wants you to use slices and therefore it should be our first choice until the code tells us otherwise. Understand that slices are like the game of chess, easy to learn but takes a lifetime to master. There are gotchas and things you need to be aware of, because the underlying array can be shared.
Now is a good time to read my post, Understanding Slices in Go Programming, before continuing.
The rest of this post will explain how to use a slice when dealing with an unknown capacity and what is happening underneath.
Here is an example of how to use an empty slice to manage a collection of unknown length:
import (
"fmt"
"math/rand"
"time"
)
type Record struct {
ID int
Name string
Color string
}
func main() {
// Let's keep things unknown
random := rand.New(rand.NewSource(time.Now().Unix()))
// Create a large slice pretending we retrieved data
// from a database
data := make([]Record, 1000)
// Create the data set
for record := 0; record < 1000; record++ {
pick := random.Intn(10)
color := "Red"
if pick == 2 {
color = "Blue"
}
data[record] = Record{
ID: record,
Name: fmt.Sprintf("Rec: %d", record),
Color: color,
}
}
// Split the records by color
var red []Record
var blue []Record
for _, record := range data {
if record.Color == "Red" {
red = append(red, record)
} else {
blue = append(blue, record)
}
}
// Display the counts
fmt.Printf("Red[%d] Blue[%d]\n", len(red), len(blue))
}
When we run this program we will get different counts for the red and blue slices thanks to the randomizer. We don't know what capacity we need for the red or blue slices ahead of time. This is a typical situation for me.
Let's break down the more important pieces of the code:
These two lines of code create a nil slice.
var blue []Record
A nil slice has a length and capacity of 0 with no existing underlying array. To add items to the slice we use the built in function called append:
blue = append(blue, record)
The append function is really cool and does a bunch of stuff for us.
Kevin Gillette wrote this in the group discussion I started:
(https://groups.google.com/forum/#!topic/golang-nuts/nXYuMX55b6c)
In terms of Go specifics, append doubles capacity each reallocation for the first few thousand elements, and then progresses at a rate of ~1.25 capacity growth after that.
I am not an academic but I see the use of tilde (~) quite a bit. For those of you who don't know what that means, it means approximately. So the append function will increase the capacity of the underlying array to make room for future growth. Eventually append will grow capacity approximately by a factor of 1.25 or 25%.
Let's prove that append is growing capacity to make things more efficient:
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
var data []string
for record := 0; record < 1050; record++ {
data = append(data, fmt.Sprintf("Rec: %d", record))
if record < 10 || record == 256 || record == 512 || record == 1024 {
sliceHeader := (*reflect.SliceHeader)((unsafe.Pointer(&data)))
fmt.Printf("Index[%d] Len[%d] Cap[%d]\n",
record,
sliceHeader.Len,
sliceHeader.Cap)
}
}
}
Here is the output:
Index[1] Len[2] Cap[2]
Index[2] Len[3] Cap[4] - Ran Out Of Room, Double Capacity
Index[3] Len[4] Cap[4]
Index[4] Len[5] Cap[8] - Ran Out Of Room, Double Capacity
Index[5] Len[6] Cap[8]
Index[6] Len[7] Cap[8]
Index[7] Len[8] Cap[8]
Index[8] Len[9] Cap[16] - Ran Out Of Room, Double Capacity
Index[9] Len[10] Cap[16]
Index[256] Len[257] Cap[512] - Ran Out Of Room, Double Capacity
Index[512] Len[513] Cap[1024] - Ran Out Of Room, Double Capacity
Index[1024] Len[1025] Cap[1280] - Ran Out Of Room, Grow by a factor of 1.25
If we look at the capacity values we can see that Kevin is absolutely correct. The capacity is growing exactly as he stated. Within the first 1k of elements, capacity is doubled. Then capacity is being grown by a factor of 1.25 or 25%. This means that using a slice in this way will yield the performance we need for most situations and memory won't be an issue.
Originally I thought that a new slice value would be created for each call to append but this isn't the case. A copy of red is being copied on the stack when we make the call to append. Then when append returns, another copy is made using the existing memory we already had.
In this case the garbage collector is not involved so we have no issues with performance or memory at all. My C# and reference type mentality strikes me down again.
Hold on to your seat because there are changes coming to slices in the next release.
Dominik Honnef has started a blog that explains, in plain english (Thank You), what is being worked on in Go tip. These are things coming in the next release. Here is a link to his awesome blog and the section on slices. Read it, it is really awesome.
http://dominik.honnef.co/go-tip/
http://dominik.honnef.co/go-tip/2013-08-23/#slicing
There is so much more you can do with slices. So much so that you could write an entire book on the subject. Like I said earlier, slices are like chess, easy to learn but takes a lifetime to master. If you are coming from other languages like C# and Java then embrace the slice and use it. It is the Go way.



